

Begun, The Catalog Wars Have
Data lake catalogs are pretty important and vendors are figuring this out.

Data lake catalogs have seen a flurry of activity over the past few weeks. Snowflake announced an open source catalog called Polaris. Databricks followed by open sourcing a reimplementation of their Unity catalog (more on this in a subsequent post). And Databricks acquired Tabular﹩, a company formed around Apache Iceberg.
There’s a lot to unpack here: Why did Snowflake create Polaris? What did Databricks actually open source? Why was Tabular acquired? Why is there so much interest in catalogs? I plan to write about catalogs in my next few posts. In this post, I want to explore why catalogs are getting so much attention.
Before continuing, readers should know that I owned Tabular shares. I don’t have any particular visibility into Databricks or Tabular’s product strategy, and I’ve tried to be as fair as possible in this post.
My use of the term “data lake catalog" in the first paragraph is a good starting point. I wasn’t sure exactly what to call these things. “Catalog” is an overloaded term. In the past, I’ve associated data catalogs with data discovery, observability, and governance use cases—Datahub, Amundsen, Alation, and OpenMetadata. Such catalogs are built for an organization’s internal data consumers like data engineers, business analysts, data scientists, and product managers.
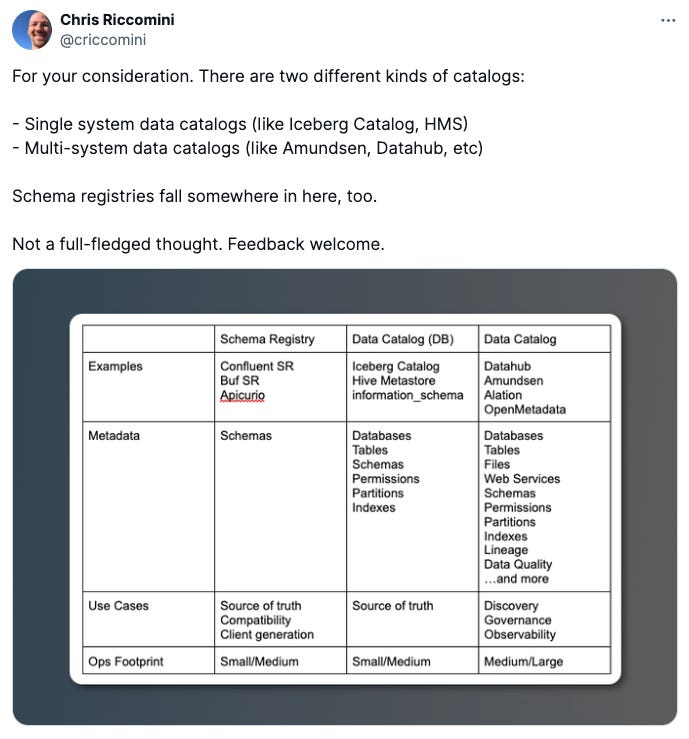
Unity, Polaris, and other data lake catalogs have some overlap with “traditional” data catalog users and use cases, but their primary purpose (in my mind, at least) is to serve as an information_schema for data warehouse query engines like Flink, Spark, Trino, and Daft. Query engines need to know which tables are available, what the column types are, and so on. Catalogs provide this information; they sit below query engines and above table formats in the composable data stack.

Table formats—the layer below catalogs—are necessary but insufficient. A table format defines a single table as a collection of files made up of rows and columns with metadata such as types and statistics. Query engines want to know about all of the databases, tables, and partitions that exist. Iceberg’s concepts page does a good job explaining the relationship between catalogs and tables:
You may think of Iceberg as a format for managing data in a single table, but the Iceberg library needs a way to keep track of those tables by name. Tasks like creating, dropping, and renaming tables are the responsibility of a catalog. Catalogs manage a collection of tables that are usually grouped into namespaces. The most important responsibility of a catalog is tracking a table's current metadata, which is provided by the catalog when you load a table.
Table formats like Iceberg, Hudi, and Delta always struck me as an odd layer for companies to fight over. The formats themselves are specifications that define a file, folder, and byte structure in a filesystem. It felt akin to building companies around storage formats like Parquet or ORC.
The layer above the table format—the catalog—is the more important layer; it’s where query engines integrate. All of the major table formats have moved upwards, growing a catalog. An integrated catalog, table format, and file format is compelling. Such a product contains the entry point to the data plane and much of the data plane itself. It is a good point to move further up the stack into the query engine layer.
A dominant catalog company could represent a significant threat if the company chose to move up the stack by offering or even favoring a query engine. Another vendor taking control of the data layer could be quite disruptive. So we see vendors moving down the stack to shore up their product offerings.
Honestly, I think some consolidation is good. It does give me some pause to see such close ties between the vendors, the catalogs, their APIs, and the query engines. I plan to write about this topic next week.
Part two in this series is available here:


Jobs
BlueArc - A former co-worker, John Canfield, is looking to hire a head of platform for BlueArc. The team is building an automated workflow engine and knowledge graph for payment risk decisioning. Risk in payments has all the best tech in it—graph databases, stream processing, realtime OLAP, AI, search indexing, and a lot more. If this is your gig, apply here.
Book
Support this newsletter by purchasing The Missing README: A Guide for the New Software Engineer for yourself or gifting it to someone.

Disclaimer
I occasionally invest in infrastructure startups. Companies that I’ve invested in are marked with a ﹩ in this newsletter. See my LinkedIn profile for a complete list.
> Data lake catalogs have seen a flurry of activity over the past few weeks
I'm also announcing a catalog :)
https://kevinjqliu.substack.com/p/introducing-the-pythonic-iceberg
> Before continuing, readers should know that I owned Tabular shares.
nice!
> The layer above the table format—the catalog—is the more important layer; it’s where query engines integrate. All of the major table formats have moved upwards, growing a catalog. An integrated catalog, table format, and file format is compelling. Such a product contains the entry point to the data plane and much of the data plane itself. It is a good point to move further up the stack into the query engine layer.
Interoperable catalogs are even more important! With Iceberg REST catalog specification, companies can bring their own catalog (data plane) to any vendor.
Spark Streaming and Flink operate on Kafka topics - so I'm curious why the catalog providers are n't supporting native Kafka topics in their metadata catalogs. Ideally a single catalog would have all my tables and topics.
With Confluent's adoption of Iceberg via TableFlow maybe they saw the writing on the wall?