

Yes, Change Data Capture Still Breaks Database Encapsulation
Stream processors and outboxes don't fix change data capture. Engineers need a tool that versions streams, detects changes, and helps manage schema evolution.

I finally made time to read Gunnar Morling’s post, “Change Data Capture Breaks Encapsulation”. Does it, though? Gunnar’s post is a response to my criticism in, Kafka change data capture breaks database encapsulation. My criticism of CDC is that it exposes internal database schemas to downstream consumers. This leads to bad things™, which Gunnar documents well:
Your table model becomes your API: by default, your table’s column names and types correspond to fields in the change events emitted by the CDC tool. This can yield less-than-ideal event schemas, particularly for legacy applications.
Fine-grained events: CDC event streams typically expose one event per affected table row, whereas it can be desirable to publish higher-level events to consumers. An example of this would be wanting one event for one purchase order with all its order lines, even if they are stored within two separate tables in an RDBMS. The loss of transaction semantics in CDC event streams can aggravate that concern, as consumers cannot easily correlate the events originating from one and the same transaction in the source database.
Schema changes might break things: Downstream consumers of the change events will expect the data to adhere to the schema known to them. As there is no abstraction between your internal data model and consumers, any changes to the database schema, such as renaming a column or changing its type, could cause downstream event consumers to break, unless they are updated in lockstep.
You may accidentally leak sensitive data: a change event stream will, by default, contain all the rows of a table with all its columns. This means that sensitive data which shouldn’t leave the security perimeter of your application could be exposed to external consumers.
Gunnar proposes data contracts as the solution to these problems. Contracts, according to the post, define data schemas, data semantics, SLAs, schema evolution rules, metadata, governance policies, examples, and so on. These are precisely the things I want (and expect) from a data contract solution for change data capture. I agree that data contracts address change data capture’s problems.
Gunnar’s then suggests that users can implement data contracts with the outbox pattern or stream processing. This is where the post loses me.
Having established that explicitly designed data contracts are very useful, how can you go about implementing them—specifically event schemas and their evolution—for your CDC events? In the following, I’d like to describe two approaches for doing so: the Outbox Pattern, and stream processing using something like Apache Flink.
The outbox pattern encourages application developers to write their “messages” to an “outbox” table in the database. The outbox table has a separate schema from the application’s internal tables and can be captured separately. This pattern gives developers the ability to evolve internal and external schemas independently while maintaining transaction boundaries.
The stream processing pattern moves the schema transformation out of the database (as it is with outboxes) and into a stream processor. Developers capture their “internal” table streams, transform them into public events, and then emit the events to a “public” stream.
These are definitely both viable ways to transform private data into public streams. But neither of these actually implement data contracts as described above. The disconnect between the problem and Gunnar’s proposed solution is what bothers me about the post.
Developers need a solution that helps them define and detect compatibility and governance rules, define SLAs for data quality, and so on. Neither stream processors nor the outbox pattern do this.
The post seems to ask developers to roll their own solution with some combination of schema definitions (Protobuf, Avro), stream processors (Flink), schema registries (Confluent Schema Registry or Apicurio), API definitions (AsyncAPI), governance tools, data catalogs, and so on. To an application developer, this feels like your data team is giving you the middle finger.
Application developers want an integrated solution that makes it easy to safely evolve schemas and maintain SLAs. Last year, I put a Twitter thread up that describes what such a solution looks like.

I want a single product that allows application developers to define their public facing streams (schemas, semantics, ownership, SLAs, and so on), and that provides tools to help detect and manage SLA violations (be they schema incompatibilities, PII leakage, data loss, semantic violations, and so on).
But the hardest part of data contracts aren’t even the tools, it’s managing the data culture at organizations. My team at WePay built a very minimal schema enforcement tool and almost immediately discovered how fraught this is.
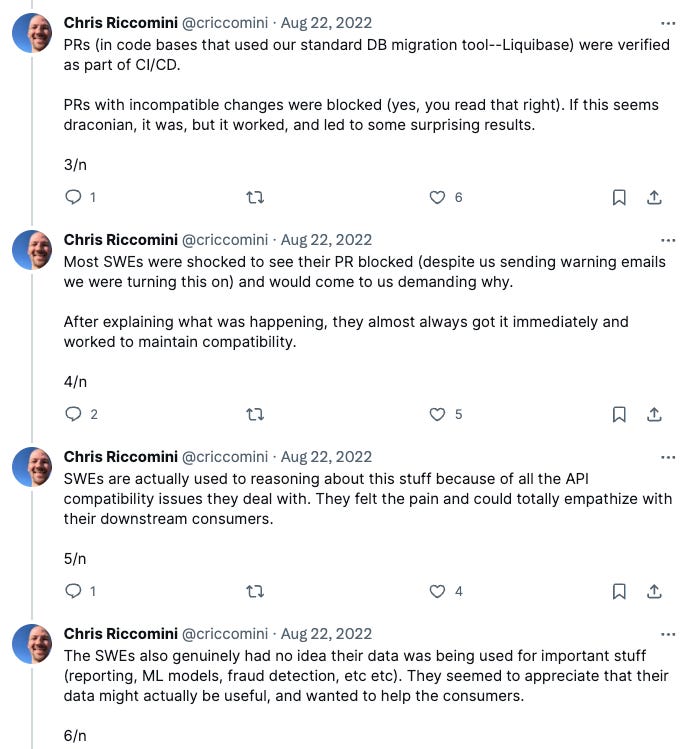
Engineers discovering their data is consumed downstream is but one gentle example of cross-team coordination complexity. Others include who owns data, what the priority is for a schema change that breaks compatibility, how important data quality is, who is paying for data processing, and so on.
Throwing more tools at the problem without addressing culture is not going to help. I discuss this in, What the Heck is a Data Mesh?!. Culture is also central to Chad Sanderson’s view, as outlined in The Rise of Data Contracts. (Chad is a vocal data contract proponent with a wealth of writing on the subject.)
To Gunnar’s credit, he does call out, “crossing context and organizational boundaries,” and proposes data contracts as the solution. This very much aligns with Chad’s view of data contracts. But outbox tables and stream processors don’t solve these complex cultural issues. At best, they’re a very small implementation detail—one small part of a much larger solution. We need tools that facilitate cross-team collaboration. Many argue that tools aren’t the solution to culture issues at all, but I digress.
I would love to have a product that helps developers create and maintain data contracts for CDC pipes; one that helps companies navigate all of a data ecosystem’s complexities. Basically, a solution that solves the problems Gunnar lists in his post. This is why I invested in Gable [$]. Chad and team are building this solution. AsyncAPI also looks to be headed in the right direction. These are the kinds of products I’d use to decouple private and public data feeds, not Flink or outbox tables.
Support this newsletter by purchasing The Missing README: A Guide for the New Software Engineer for yourself or gifting it to someone.

I occasionally invest in infrastructure startups. Companies that I’ve invested in are marked with a [$] in this newsletter. See my LinkedIn profile for a complete list.