

SQLite’s Tricky Type System, Durable Execution Moves up the Stack, and HikariCP Is Too Fast...
Everything you need to know about SQLite's type system; Shower thoughts on durable execution, workflows, and their user interfaces; and HikariCP is a giant performance flex.

I joined Ryan Blue, Wes McKinney, and Pedro Pedreira to talk about composable data systems on The Data Stack Show. If you enjoyed my last post on disassembled databases, check out The Parts, Pieces, and Future of Composable Data Systems.
Demystifying SQLite’s Type System
It’s been a rainy week here in the bay area. I’ve spent much of it working on Recap’s SQLite client and converter. I did some reading on SQLite’s type system while doing so. It has some surprising behavior. Given SQLite’s widespread adoption—especially in tests—I want to highlight some peculiarities.
SQLite’s type system has three important concepts: datatypes, storage classes, and column affinities. SQLite’s datatypes define how data is written to disk (think variable length integers, zigzag encoding, and so on). Its storage classes define how data is stored in memory. There are just five storage classes: NULL, INTEGER, REAL, TEXT, and BLOB.
A storage class is more general than a datatype. The INTEGER storage class, for example, includes 7 different integer datatypes of different lengths. This makes a difference on disk. But as soon as INTEGER values are read off of disk and into memory for processing, they are converted to the most general datatype (8-byte signed integer). And so for the most part, "storage class" is indistinguishable from "datatype" and the two terms can be used interchangeably.
To understand column affinities—the last concept—you must first know that SQLite ignores column types (unless STRICT is used). A value of any type can be written to any column. But rather than ditch column types completely, SQLite uses column affinities to convert data as it’s coming in.
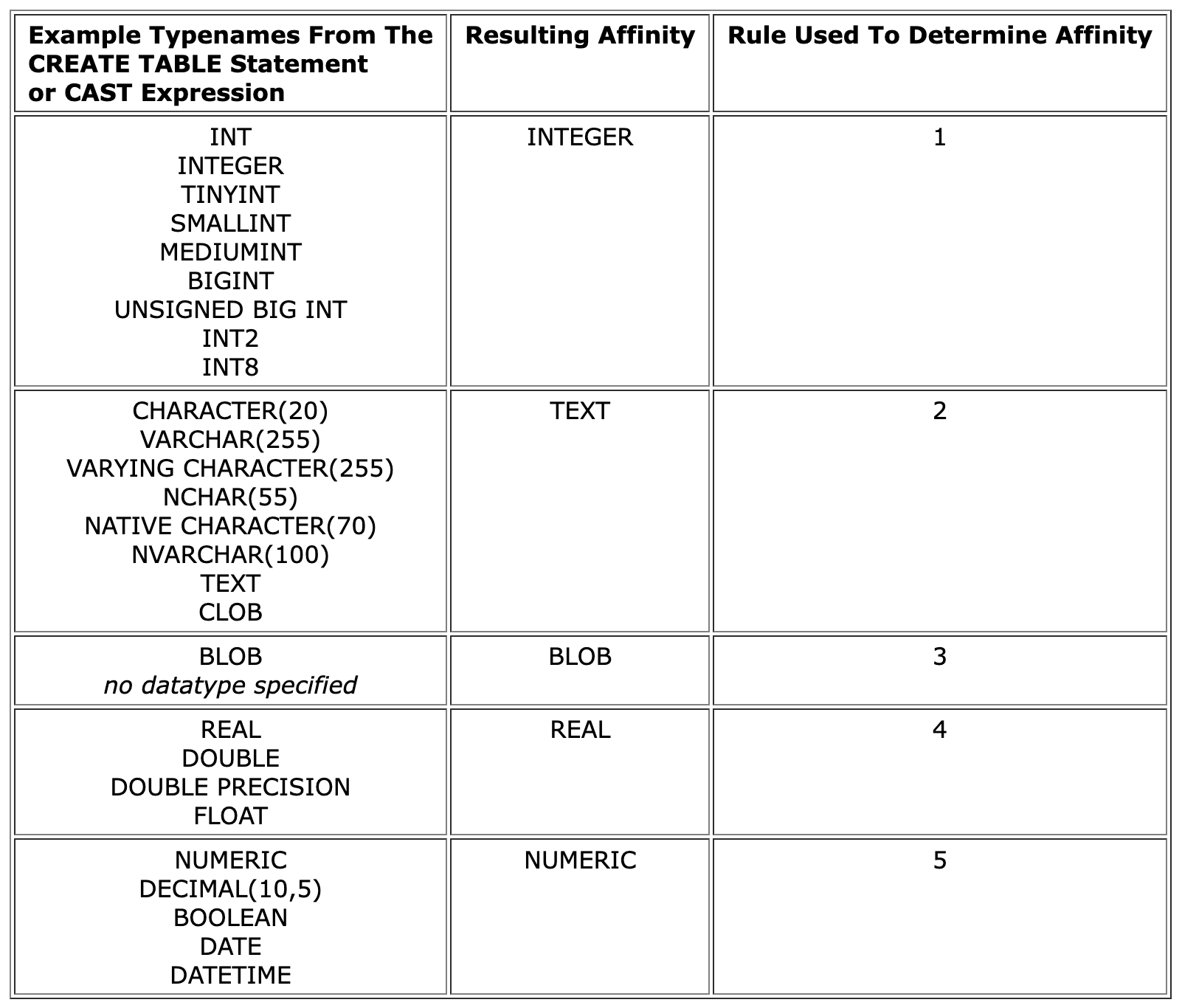
Column affinities govern how data is coerced before it’s written to disk, and to which values and columns the coercion is applied. There are five affinities: TEXT, NUMERIC, INTEGER, REAL, and BLOB (note that these are not the same as the storage classes). Here’s the TEXT affinity’s documentation:
A column with TEXT affinity stores all data using storage classes NULL, TEXT or BLOB. If numerical data is inserted into a column with TEXT affinity it is converted into text form before being stored.
To determine a column’s affinity, SQLite uses a set of text-matching rules. TEXT affinity is determined as follows:
If the declared type of the column contains any of the strings "CHAR", "CLOB", or "TEXT" then that column has TEXT affinity. Notice that the type VARCHAR contains the string "CHAR" and is thus assigned TEXT affinity.
SQLite’s column affinity documentation has a complete list of rules. My favorite is, ‘If the declared type for a column contains any of the strings "REAL", "FLOA", or "DOUB" then the column has REAL affinity.’
This can lead to some funky behavior, but SQLite does surprisingly well in normal use.
Why go to all this trouble? The Advantages of Flexible Typing claims the design better suits mixed-type table columns, dynamic programming languages, JSON, cross-compatibility with other databases, and so on.
Durable Execution as Code, Config, and UI
I spoke recently to both Temporal CEO, Maxim Fateev, and Restate’s founder, Stephan Ewen. It struck me in both conversations how different durable execution, workflow orchestration, and microservice orchestration are when defining work to execute. I see at least four different ways in which work is defined:
Config-as-code definitions (LittleHorse, Airflow, Prefect, Dagster)
GUIs seem to be popular with business process model notation (BPMN) systems. XML is unwieldy, so users ask for a UI. Camunda and Orkes both offer robust workflow builder GUIs (though I don’t believe Orkes uses BPMN).
Config definitions in YAML, JSON, or XML seem to be most popular with legacy data processing workflow systems like Azkaban and Oozie. Config-as-code has largely replaced config files in the data processing space now. Dagster, Prefect [$], and Airflow all define workflows in code.
Durable execution frameworks prefer APIs and SDKs for their flexibility. Workflows tend to be more rigid—you know the structure of the workflow beforehand. APIs and SDKs work better for dynamic execution with branching and loops.
Systems are starting to adopt more than one of these interfaces. Restate now has JSON workflow definitions. LittleHorse plans to add config and GUI support this year. And people have built home-grown config systems on Airflow for years.
This trend is unsurprising, but notable. I’ve written about how durable execution needs to move beyond traditional transactional use cases like payment processing:

These different models exist because they are well suited for different users and use cases. As durable execution systems move up the stack and workflow systems move down the stack, their addressable market (and competitors) will increase—precisely what I’ve been calling for.
Project Highlight: HikariCP
HikariCP is an in-process Java Database Connectivity (JDBC) connection pool. Rather than create a new connection for every database request, connection pools keep and reuse them. This removes the overhead of creating a new connection.
We used c3p0 at my previous job, so I wasn’t familiar with HikariCP when I saw Gwen Shapira’s recent tweet.

This is not hyperbole. HikariCP’s documentation is a gold mine. Their Down the Rabbit Hole post is a must-read for anyone fixated on Gunnar Morling’s 1brc challenge.
Gwen’s post also sparked an interesting question about in-process and out-of-process connection pools (like PgBouncer). I don’t have a good answer, but it seems worth answering. Let me know if you’ve got an answer.
Support this newsletter by purchasing The Missing README: A Guide for the New Software Engineer for yourself or gifting it to someone.

I occasionally invest in infrastructure startups. Companies that I’ve invested in are marked with a [$] in this newsletter. See my LinkedIn profile for a complete list.