

This MCP Server Could Have Been a JSON File
There's a lot of buzz around MCP. I'm not convinced it needs to exist.

Model context protocol (MCP) servers are very buzzy right now. The idea is simple: teach large language models (LLMs) how to interact with other software systems. In doing so, LLMs can learn from and affect the real world; they can call a web service to make a phone call, invoke a command line interface (CLI) tool to add an item to a grocery list in a reminder app, and so on. To make such calls, LLMs must know what software it can call and how to do so. This is the problem that MCP solves: it informs LLMs of available software, teaches the LLM how to use it, and provides an avenue through which the LLM can call the software.
Developers write MCP servers that provide resources, prompts, and tools to the LLM. The MCP site discusses these concepts in detail, but the Core MCP Concepts section provides a summary:
These categories are arbitrary and confusing. At first blush, it seems resources are read-only and tools are write-only. But the MCP server documentation uses searchFlights as their tool example—a read-only operation. Even more baffling, they later show flight searching as a resource. Here’s their tool definition:
{
name: "searchFlights",
description: "Search for available flights",
inputSchema: {
type: "object",
properties: {
origin: { type: "string", description: "Departure city" },
destination: { type: "string", description: "Arrival city" },
date: { type: "string", format: "date", description: "Travel date" }
},
required: ["origin", "destination", "date"]
}
}And here’s their resource definition:
{
"uriTemplate": "travel://flights/{origin}/{destination}",
"name": "flight-search",
"title": "Flight Search",
"description": "Search available flights between cities",
"mimeType": "application/json"
}Prompts are simply static JSON definitions that describe potential user activities.
The whole protocol feels off to me. Prompts are just static documentation, resources are static URL definitions, and tools look like remote procedure call (RPC) definitions. I asked ChatGPT 5 Thinking to convert the searchFlights tool definition to an OpenAPI definition (an actual RPC definition). Unsurprisingly, it worked just fine:
openapi: 3.0.0
info:
title: Flights API
version: "1.0.0"
paths:
/searchFlights:
get:
operationId: searchFlights
summary: Search for available flights
description: Search for available flights
parameters:
- in: query
name: origin
required: true
description: Departure city
schema:
type: string
- in: query
name: destination
required: true
description: Arrival city
schema:
type: string
- in: query
name: date
required: true
description: Travel date
schema:
type: string
format: date
responses:
"200":
description: Search results
content:
application/json:
schema:
type: array
items:
type: objectThis begs the question: why do we need MCP for tool definitions? We already have OpenAPI, gRPC, and CLIs. ChatGPT understands OpenAPI definitions. Millions of web services already provide OpenAPI definitions, too. And ChatGPT is actually better at CLIs than most humans—just watch Codex fly through sed, awk, and grep commands. A friend recently informed me that they successfully taught ChatGPT to use tmux. MCP vs CLI: Benchmarking Tools for Coding Agents reflects this sentiment:
MCP vs CLI truly is a wash: Both
terminalcpMCP and CLI versions achieved 100% success rates. The MCP version was 23% faster (51m vs 66m) and 2.5% cheaper ($19.45 vs $19.95).
I’ve seen several arguments made to justify MCP’s existence:
LLMs have a limited context window. OpenAPI documentation takes up too much context space.
Many services are not well documented; they don’t come with an API spec.
LLMs need a way to discover what tools are available to it.
I’m skeptical. Perhaps MCP does allow us to squeeze a few more tools into the context window. Perhaps it does let models run a little faster. OpenAPI documents are indeed somewhat verbose. But for how long will this matter?
Last year we were talking about 1 million token models. Now, we have 2 million token models in OpenRouter. Smaller models, fine tuning, and other research also continues apace. Viewed from this lens, MCP seems like a temporary kludge.
The final argument that many services have poor documentation is true for internal enterprise services. Jake Mannix makes this point in his recent thread. I hear that MCP is most widely adopted for this segment.
Customer-facing SaaS APIs are a different story. Most are remarkably well documented. Some are complex, but these are often inherent complexities (I can attest to this after working with WePay’s API).
Moreover, the argument seems to be that the same people that wrote the bad OpenAPI specs are going to write good MCP specs. I don’t buy it. (And again, even if they could do this, why not write the endpoint as an OpenAPI endpoint or a CLI tool?)

As for discovery, I accept that LLMs need to know where tools are and how to use them. But this is static content. We already have AGENTS.md, .github/instructions, openapi.json, and so on.
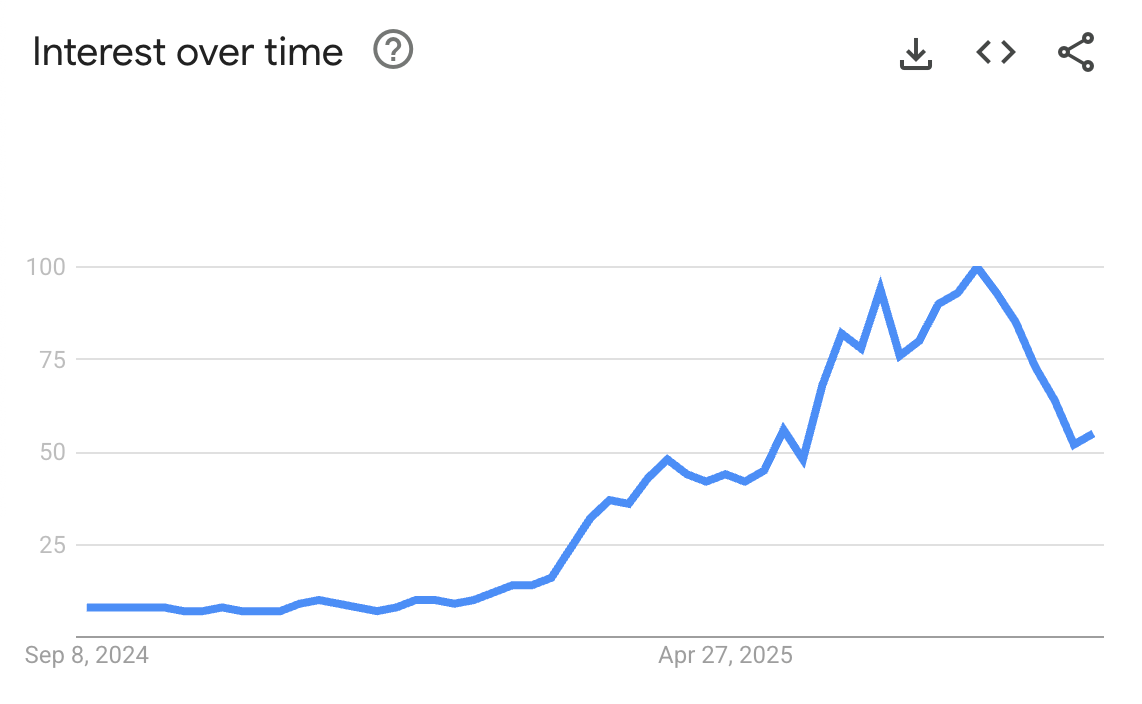
Developers are waking up to this. Bruin﹩ is using MCP just to expose documentation; their tool calls are done through normal CLI commands. Donobu﹩ simply provides an OpenAPI spec. Both solutions work. Meanwhile, MCP’s Google trend looks bleak.
I don’t blame the MCP authors for this mess. Things happen fast in the AI ecosystem. MCP is a victim of its own success. MCP: An (Accidentally) Universal Plugin System does a good job explaining the situation.
We need to take a step back and think about what we’re trying to accomplish. There’s no law that LLMs need a new protocol to interact with software. In most cases, we have what we need. Where we don’t, we should write CLIs, web services, and documentation using existing standards.
My takeaway? Maybe instead of arguing about MCP vs CLI, we should start building better tools. The protocol is just plumbing. What matters is whether your tool helps or hinders the agent's ability to complete tasks.
—Mario Zechner, MCP vs CLI: Benchmarking Tools for Coding Agents
Book
Support this newsletter by purchasing The Missing README: A Guide for the New Software Engineer for yourself or gifting it to someone.

Disclaimer
I occasionally invest in infrastructure startups. Companies that I’ve invested in are marked with a ﹩ in this newsletter. See my LinkedIn profile and Materialized View Capital for a complete list.