

The Internet Gets Faster With L4S, Terminal Benchmarking Tools, Zed Unifies Data Models, and more...
There's a new protocol to save streaming; 1brc elevates some cool terminal benchmarking tools; and I compare Zed to Recap.

Materialized View crossed 1,000 subscribers in January! It’s encouraging to see such growth, and to get positive feedback. I just want to say thank you for subscribing.
Low Latency, Low Loss, Scalable Throughput (L4S)
A friend (and Apple fanboy) recently pointed me at Apple’s Low Latency, Low Loss, Scalable throughput (L4S) WWDC 2023 video. L4S is a new architecture from the IETF that optimizes internet bottlenecks.
… L4S is based on the insight that the root cause of queuing delay is in the capacity-seeking congestion controllers of senders, not in the queue itself. With the L4S architecture, all Internet applications could (but do not have to) transition away from congestion control algorithms that cause substantial queuing delay and instead adopt a new class of congestion controls that can seek capacity with very little queuing. These are aided by a modified form of Explicit Congestion Notification (ECN) from the network. With this new architecture, applications can have both low latency and high throughput.
Realtime applications—video and gaming—are an important part of our lives. These applications don’t do well when their network path is congested; users see stalls in their video, audio, or game. Lag is caused when slowest hop in a network traversal can’t keep up. Packets begin to queue, which causes lag and eventually a stall.
L4S reduces queuing and packet loss in the network to eliminate these stalls. Clients set an explicit congestion notification (ECN) bit in the packets they send. This bit signals that they support L4S. When a server in the network path begins to queue packets it receives, it marks the queued packets with a bit. The server (the final destination of the packet) counts flagged packets and reports back to the client. The client can then slow down its send rate.
Apple’s WWDC video shows a real-world demo and compares RTT and packet loss metrics.
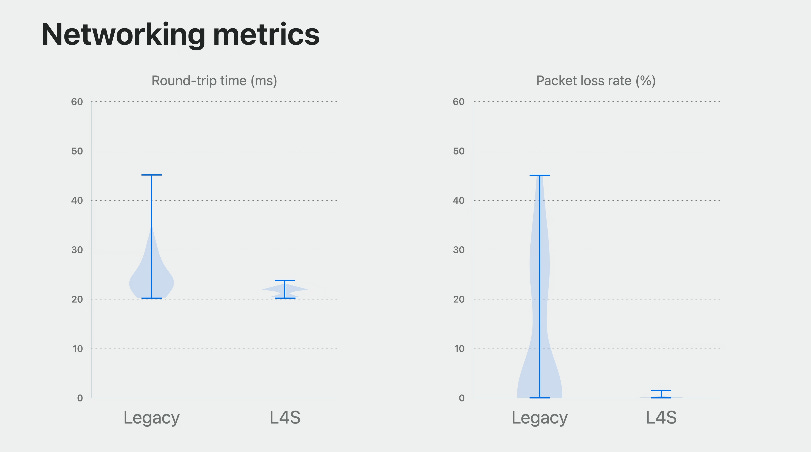
The drop in tail latency notable, as this is where stalls are most egregious.
Since L4S sits low in the network stack—in both layer 3 (IP) and layer 4 (TCP/UDP) of the OSI model—your code should automatically benefit without any changes. The OS and routing hardware are what need to evolve. Apple, Google and ISPs are all working together to support L4S. On Mac, L4S is automatically supported in OS X Sonoma when using HTTP/3, QUIC, HTTP/2, or TCP. On Linux, there’s a Github repo containing the requisite kernel patches.
Terminal Benchmarking Tools
Gunnar’s 1brc challenge has elevated a bunch of benchmarking tools. Three that caught my eye are hyperfine, poop, and flameshow. All three are terminal tools.
Hyperfine is by far the most popular. It’s a glorified time command with a bunch of cool features:
Statistical analysis across multiple runs.
Support for arbitrary shell commands.
Constant feedback about the benchmark progress and current estimates.
Warmup runs can be executed before the actual benchmark.
Cache-clearing commands can be set up before each timing run.
Statistical outlier detection to detect interference from other programs and caching effects.
Export results to various formats: CSV, JSON, Markdown, AsciiDoc.
Parameterized benchmarks (e.g. vary the number of threads).
Cross-platform

Poop is similar, but has a most excellent name. Unlike Hyperfine, it only runs on Linux so it can take advantage of perf_event_open.
However, poop does report peak memory usage as well as 5 other hardware counters, which I personally find useful when doing performance testing. Hey, maybe it will inspire the Hyperfine maintainers to add the extra data points!
Poop does not run the commands in a shell. This has the upside of not including shell spawning noise in the data points collected, and the downside of not supporting strings inside the commands.
Flameshow is a terminal FlameGraph viewer that supports both pprof and FlameGraph formats. From the original ACM article, The Flame Graph:
A flame graph visualizes a collection of stack traces (aka call stacks), shown as an adjacency diagram with an inverted icicle layout. Flame graphs are commonly used to visualize CPU profiler output, where stack traces are collected using sampling.
Max Rydahl Andersen shows how to use flamegraph with the JVM for 1brc:

Project Highlight: Zed
Zed is an umbrella project for a collection of data lake tools. The project includes a data model, storage format(s), transactional table format, query language, and more.
Zed’s data model is what I’m most interested in. I’ve been working on Recap for the past year. Recap lets you work with web service, database, and streaming schemas in a single format. Zed’s data model has a very similar goal:
Zed is a new data model that unifies the JSON and relational models to make data as easy as ever.
I am happy to see that Zed’s data model is very similar to Recap’s. We both made the same design choices independently. This is validating and bodes well for both projects.
Zed, however, is a much more ambitious project than Recap. It includes serialized formats (ZNG, VNG, ZSON, ZJSON), a query language, and more. I can’t speak to the whole tool chain, but the data model looks well thought out. If you’re using Zed I’d love to hear about it.
So when should you pick Zed, and when should you pick Recap for your projects? Zed is a much larger ecosystem; if you want serialization or data lake table formats, it’s the right call.
Recap is much slimmer; it deliberately limits itself to reading, writing, and converting between service, event, and database schemas. Recap also has a slightly more robust model allowing for things like logical types, required fields, fixed length arrays and maps, and so on. I suggest Recap if your main use case is data modeling or schema conversion. Gable [$] is using Recap as their data model and I would love to see more adoption.
More Awesome Infrastructure
Keep up with new infrastructure projects as they’re added to awesome-infra. New submissions are welcome!
optd - CMU-DB's Cascades optimizer framework for query engines. Currently, optd is integrated into Apache Arrow Datafusion as a physical optimizer.
You can support me by purchasing The Missing README: A Guide for the New Software Engineer for yourself or gifting it to new software engineers that you know.
I occasionally invest in infrastructure startups. Companies that I’ve invested in are marked with a [$] in this newsletter. See my LinkedIn profile for a complete list.