

Unpacking the Buzz around ClickHouse
A look at the excitement around ClickHouse. I break down what makes it great and the challenges ahead.

I have some exciting news! I’m helping Martin Kleppmann with the second edition of his popular book, Designing Data-Intensive Applications. Martin and I first met at LinkedIn, where we worked together on Apache Samza. I’m very excited to contribute in a small way to such an important and popular book. An early release of the first three chapters are now available to O’Reilly Learning subscribers, with more to come. See Martin’s post for more details.
I also had a very pleasant conversation in the inaugural episode of Tech on the Rocks. We discussed stream processing, Rust, SlateDB, and more. Give it a listen here:
My two previous posts, 15 Years of Realtime OLAP (part 1, part 2), documented my experience with home-grown realtime OLAP systems, Apache Druid, and Apache Pinot. I also discussed the use cases I had for these systems: user facing product analytics and fraud detection. My intent was to lay the foundation for this post, where I investigate the buzz around ClickHouse.
ClickHouse has been appearing a lot in some of my recent interactions. Tinybird, a user-facing analytics product, uses ClickHouse as its database. Several startups I’ve talked to are working on ClickHouse-related products. My Twitter feed has a lot of ClickHouse mentions, too.
What’s more, much of the feedback about ClickHouse appears to be quite positive, too. This caught my eye—we engineers tend to be a critical bunch. Moreover, when I looked at ClickHouse, I saw another realtime OLAP system like Druid or Pinot. Why all the attention?

The responses to this post were interesting. The feedback seems to boil down to three things: speed, ease of install, and ease of operations.

Speed
ClickHouse is indeed very fast. A friend told me, “They have the mentality of a team on a budget. Like they didn’t have 1000s of machines to throw at the problem. They had to make it work on what they had.” This might or might not be true—ClickHouse comes from Yandex—but the software definitely has this vibe.
As proof, ClickHouse runs a benchmark project. Database vendors may submit their databases to see how they fair. ClickHouse has been dominating its competition (at least until 6 months ago when Umbra showed up). One can quibble over the workloads tested, but ClickHouse is clearly a very fast database.
Installation
Though speed is nice, it’s not as important as it used to be. Where ClickHouse really shines is its installation experience. Realtime OLAP systems are notoriously annoying to get running. Apache Druid and Apache Pinot both use bash scripts that spawn multiple local JVM-based services to get the system up and running. Either that or you’ve got to run Docker and use Helm charts, as is the case with StarRocks.
ClickHouse, by contrast, is a single cURL command to clickhouse.com. The server is smart enough that it recognizes the lack of user-agent in the HTTP request and automatically gives you a bash script to install a native binary for your host. It just works.

They’ve occupied a really nice spot between embedded OLAP systems like DuckDB and distributed realtime OLAP systems like Apache Pinot and Apache Druid. It’s surprising to me that there aren’t more single-process realtime OLAP systems out there; it seems obvious in hindsight. ClickHouse seems unique in this regard, aside from recent PostgreSQL OLAP developments (more on this later).
Another way of phrasing all this is that the developer experience (DX) is really nice. And a great developer experience leads to a lot of rave reviews on Twitter. I suspect this is where a lot of the buzz is coming from.
Operations
A great DX is nice and all, but does it scale and is it easy to operate? Here too, the feedback is positive, but more mixed. ClickHouse’s speed and efficiency mean it can scale up quite nicely—you can continue to run it on one big machine for quite a while.

Once you’re ready to move beyond one machine, you’ll need to introduce another ClickHouse service: ClickHouse Keeper. Here, too, the developer experience is excellent. ClickHouse used to rely on ZooKeeper to coordinate its nodes in a distributed environment. Running ZooKeeper is tough, so ClickHouse wrote their own drop-in replacement, which they bundle bundle into their binary.

The operational flexibility to scale up or out without adding a bunch of services is really valuable. And it’s run on some very large workloads. Tinybird has some customers doing 300K-600K events per second. Uber adopted ClickHouse for their log analytics platform (more on this later, too). And I assume Yandex’s usage is still fairly large.
Of course, there will always be operational challenges. Javi Santana, Tinybird’s co-founder, says it’s, “super hard to run at scale.” I also noticed some discussion about disk usage and imbalances. And its XML configuration files are clunky.
Challenges
As nice as ClickHouse appears to be, I see a few challenges. The first and most significant is cost. Remember Uber’s ClickHouse log system I mentioned above? They’re moving off ClickHouse. Yupeng Fu presented an excellent talk at StarTree’s﹩ RTA Summit 2024 called Evolution of OLAP at Uber. The talk discusses how Uber is replacing several pieces of infrastructure, including ClickHouse, with Apache Pinot.

Yupeng says that Uber’s log analytics platform migration in 2020 resulted in 50% cost savings when compared to their previous ELK-based log analytics system. But ELK is very expensive to run on large datasets. A 50% gain isn’t really that much. Since the migration, the team has hit cost and performance challenges. Stories like these are somewhat alarming for large-scale enterprises.
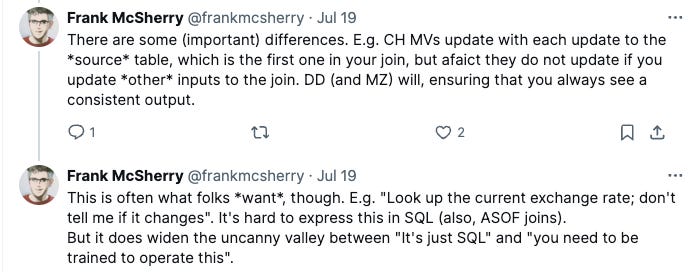
Another more subtle (and perhaps more minor) challenge with ClickHouse is its behavior with materialized views. Materialized views are important for many realtime analytics use cases. By updating aggregates when a write occurs, reads become very fast. Entire systems like Materialize and Feldera are built around this concept. ClickHouse supports materialized views, but updates are only triggered when the “main” table—the first table in a join—is written to. For many queries, especially those without joins, this is perfectly acceptable. But for more sophisticated use cases, it simply isn’t good enough.
And finally, the elephant in the room: PostgreSQL is becoming an OLAP system. Hydra recently published pg_duckdb with backing from MotherDuck, Microsoft, Neon, and others. Hydra’s extension integrates DuckDB (an even more buzzy project than ClickHouse) with PostgresSQL. And ParadeDB has seen a lot of adoption with its pg_lakehouse, pg_analytics, and pg_search PostgreSQL extensions.
As PostgreSQL’s OLAP extensions mature, it will be a great solution for the exact space that ClickHouse shines: single-node scale-up realtime OLAP with a great DX. If PostgreSQL takes ClickHouse’s single-node and small-scale usage, and systems like Pinot and Druid take its large-scale market, there’s not much left. This is the biggest long-term threat that I see for ClickHouse.
Still, as things stand now, ClickHouse is a robust system, and a reasonable solution for many use cases. I look forward to seeing how things shake out; I have a real soft spot for realtime analytics.
Book
Support this newsletter by purchasing The Missing README: A Guide for the New Software Engineer for yourself or gifting it to someone.

Disclaimer
I occasionally invest in infrastructure startups. Companies that I’ve invested in are marked with a ﹩ in this newsletter. See my LinkedIn profile for a complete list.