

DuckDB Is Not a Data Warehouse
DuckDB is a tool, not a product.

Before I get to DuckDB, I’ve got three house-cleaning items this week: Bluesky, Materialized View’s one year anniversary, and P99 CONF.
Let’s begin with social media. I’ve moved to Bluesky 🦋. Follow me @chris.blue if you’ve enjoyed my Twitter posts over the past 15 years. You can crosspost with Fedica or Buffer if you like. There are some great starter packs to bootstrap your feed, too. Here are a few:
Infrastructure Engineers (mine)
I don’t know what this means for my Twitter account. All I can say is that I’ve been using Bluesky exclusively for the past week and it’s absolutely buzzing. It feels like the good old days. I haven’t missed Twitter at all.
Next, Materialized View turned one on October 31 🎃. It’s been an incredible year for the newsletter. I’ve published 50 posts and the newsletter just passed 4,000 subscribers. I’ve also received a lot of positive feedback. Almost everyone I meet mentions Materialized View. Thanks again for all the support and encouragement.

Finally, Rohan Desai and I presented at P99 CONF and the video is now online. Along with my The Geek Narrator interview, our talk is a great starting point to learn about SlateDB’s internals.
A consequence of drinking from the dataBS firehose is that you will get a lot of DuckDB chatter. For the unfamiliar, DuckDB is essentially SQLite for columnar data. It has a number of interesting properties. It’s very portable: it runs locally on your laptop, inside an application, or even in a browser. It’s also very fast (though, I’m told that’s not enough). Most importantly, it can connect to remote storage to read Apache Parquet files and Apache Iceberg tables.
These properties have made DuckDB a favorite among analytics and data engineers. All kinds of creative DuckDB uses have popped up. Okta uses DuckDB to cheaply transform data before it enters Snowflake. MotherDuck also showcases ETL examples. Rill and Mode have both adopted DuckDB as their in-memory query engines. PostgreSQL has been overrun with DuckDb extensions such as pg_duckdb, pg_mooncake, and pg_analytics. You can even use DuckDB to query New York City taxi data straight from your laptop (or from Modal﹩).
Given that DuckDB is an online analytical processing (OLAP) database, you might expect to see stories of DuckDB replacing Snowflake, Redshift, BigQuery, or Databricks as a data warehouse. There are some, but not many. I’ve always been skeptical of the idea that DuckDB is a viable solution for an enterprise data warehouse. Ananth Packkildurai (of Data Engineering Weekly fame) posted an observation that resonated with me:

DuckDB’s deployment model and limited scalability are what I struggle with. If you’re in an enterprise, your data warehouse users are going to include product managers, customer support, risk analysts, business analysts, finance teams, operations teams—virtual everyone at the company. I don’t see how DuckDB can be deployed in such an organization. It’s untenable to install DuckDB on everyone’s laptop, grant everyone access to data lake buckets, and ask them to run queries from the CLI.
Even if a company wanted to use DuckDB as their data warehouse, they couldn’t. DuckDB can’t handle the largest queries an enterprise might wish to run. MotherDuck has rightly pointed out that most queries are small. What they don’t say is that the most valuable queries in an organization are large: financial reconciliation, recommendation systems, advertising, and others. These are the revenue drivers. They might comprise a minority of all the queries an organization runs, but they make the money. DuckDB just can’t handle such queries.
To be a viable data warehouse, DuckDB needs a centralized deployment model, a better UI, and a way to scale. This is exactly what MotherDuck is building, and it sounds a lot like Snowflake or BigQuery. As much as MotherDuck would like to be the DuckDB vendor, they’re a cloud data warehouse that just happens to use DuckDB.
This begs the question: why should I switch from my current data warehouse to MotherDuck? It seems like the answer right now is cost. Cloud data warehouses are expensive. MotherDuck saves money by running DuckDB on small data sets. But it’s also really expensive to change data warehouses. It’s often easier to cut costs in your existing data warehouse by auditing queries and data retention.
Smaller companies can adopt DuckDB or MotherDuck and scale cheaply as they grow. This is a reasonable story for SMBs, but not for enterprises that already have a warehouse. But SMBs can also adopt the PostgreSQL extensions that I mentioned earlier. If I were tasked with rolling out DuckDB in an organization, that’s probably how I’d do it.
So, on the one hand, MotherDuck has picked a fight with some of the nastiest apex predators out there: Snowflake, BigQuery, and Databricks. On the other, they’re getting squeezed by PostgreSQL extensions and DuckDB on the laptop. This is a tough environment. MotherDuck has raised a lot of money, so perhaps they can find enough SMB customers and wait for them to scale.
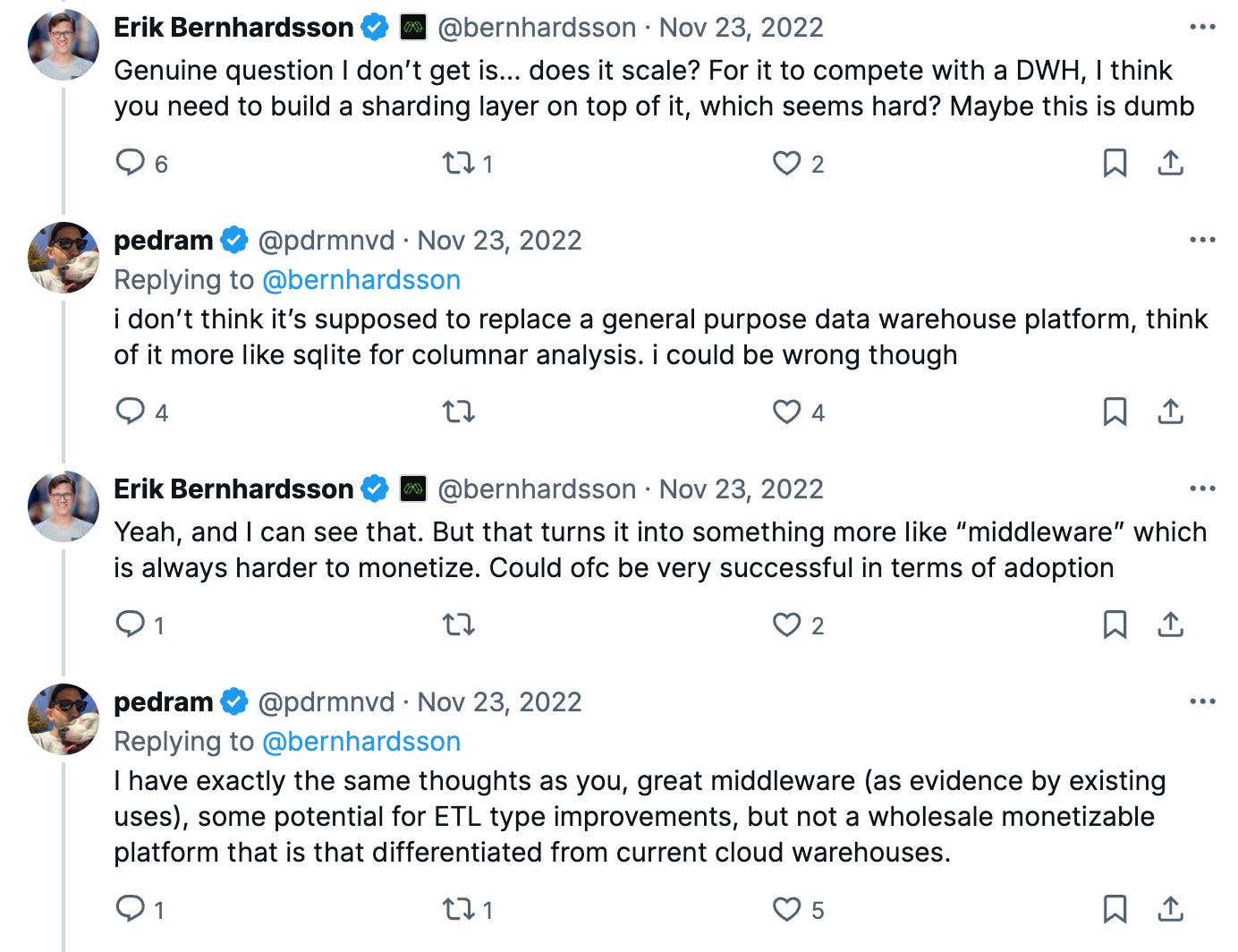
As for DuckDB itself, I think Pedram and Erik have it right in the Tweet above. It’s amazing middleware, much like SQLite. I don’t see it as a data warehouse, though.
Book
Support this newsletter by purchasing The Missing README: A Guide for the New Software Engineer for yourself or gifting it to someone.

Disclaimer
I occasionally invest in infrastructure startups. Companies that I’ve invested in are marked with a ﹩ in this newsletter. See my LinkedIn profile and Materialized View Capital for a complete list.